| α | One-tailed | Two-tailed |
|---|---|---|
| 0.10 | 1.282 | 1.645 |
| 0.05 | 1.645 | 1.960 |
| 0.01 | 2.326 | 2.576 |
| 0.001 | 3.090 | 3.291 |
P-values & Critical Values
Logic, Geometry, and Decisions
P-value: Area Beyond the Test Statistic
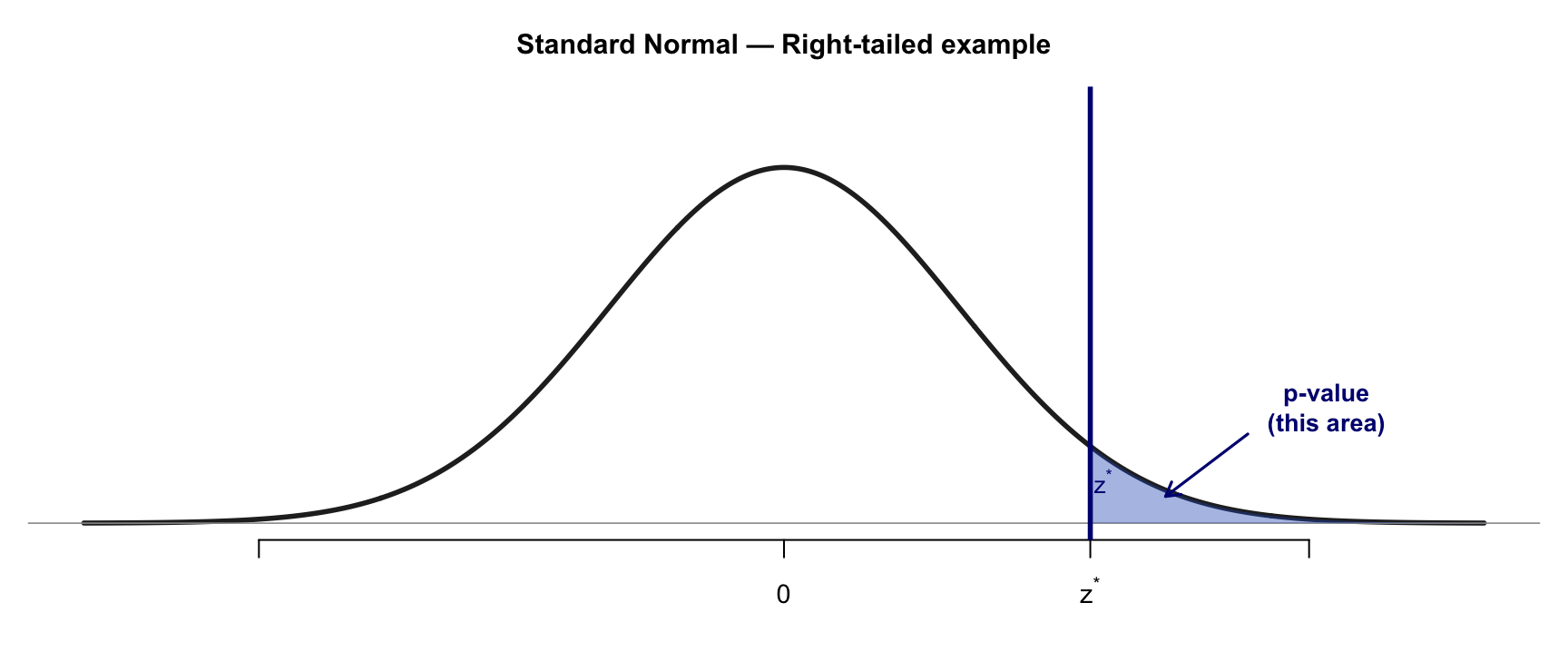
p-value = P(seeing something this extreme or more | H₀ is true)
The further z* moves into the tail → smaller area → smaller p-value → stronger evidence against H₀
Critical Value: Threshold on the X-axis
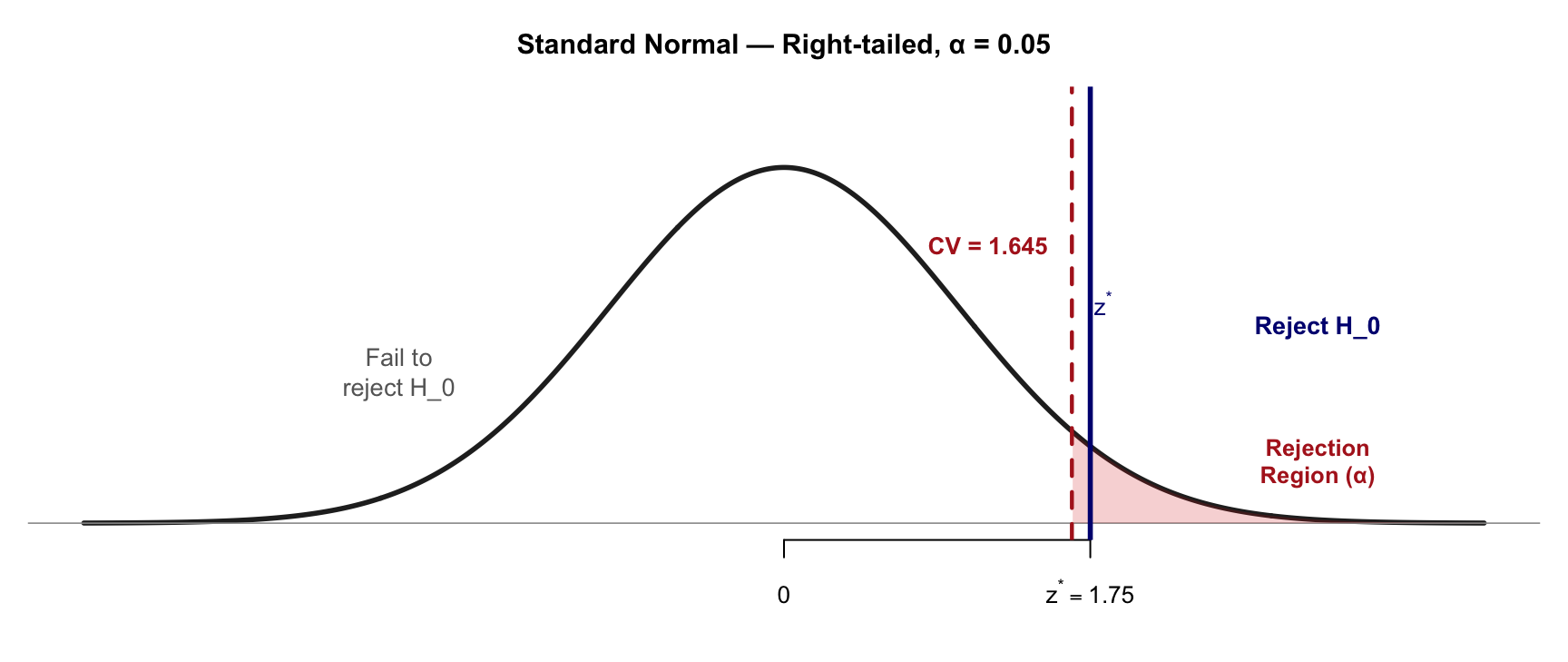
z* > CV → z* is inside the rejection region → Reject H₀
The CV cuts off exactly α in the tail; anything past it is “too extreme under H₀”
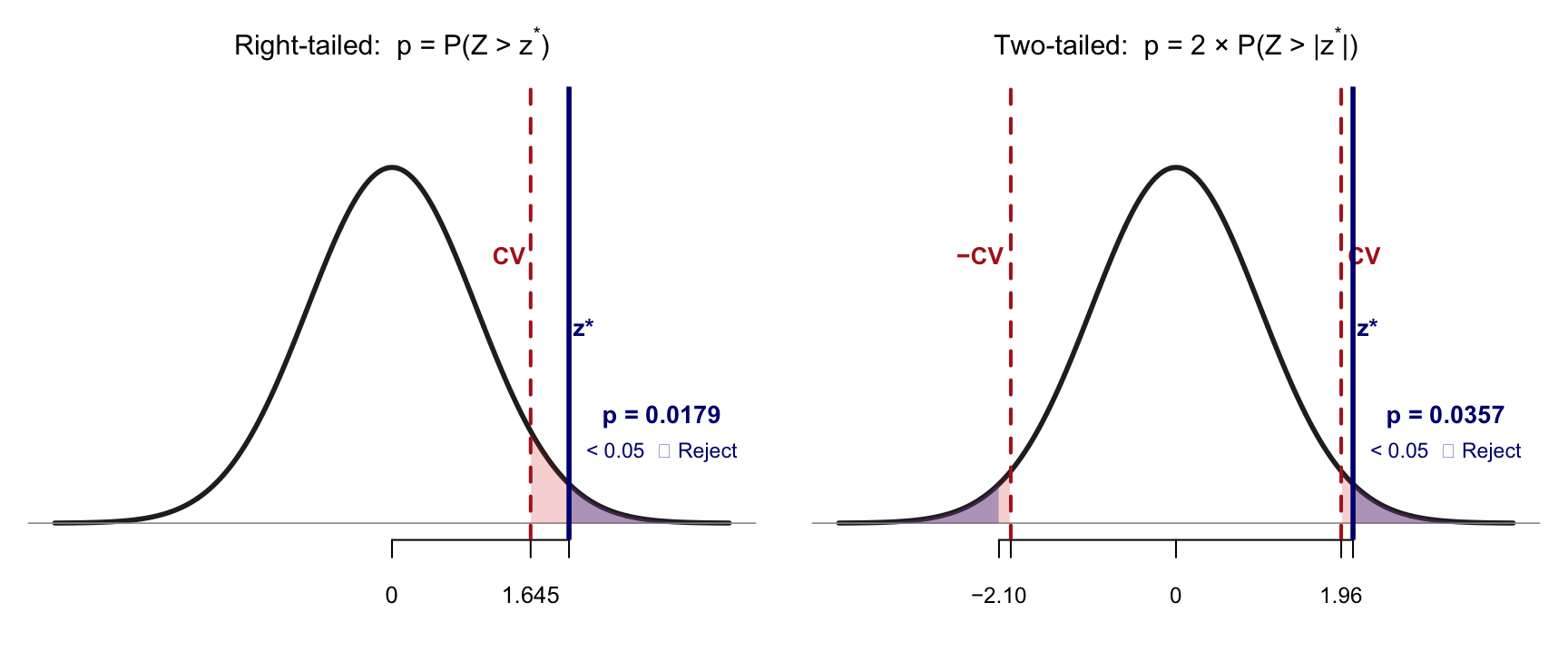
One-tailed vs Two-tailed
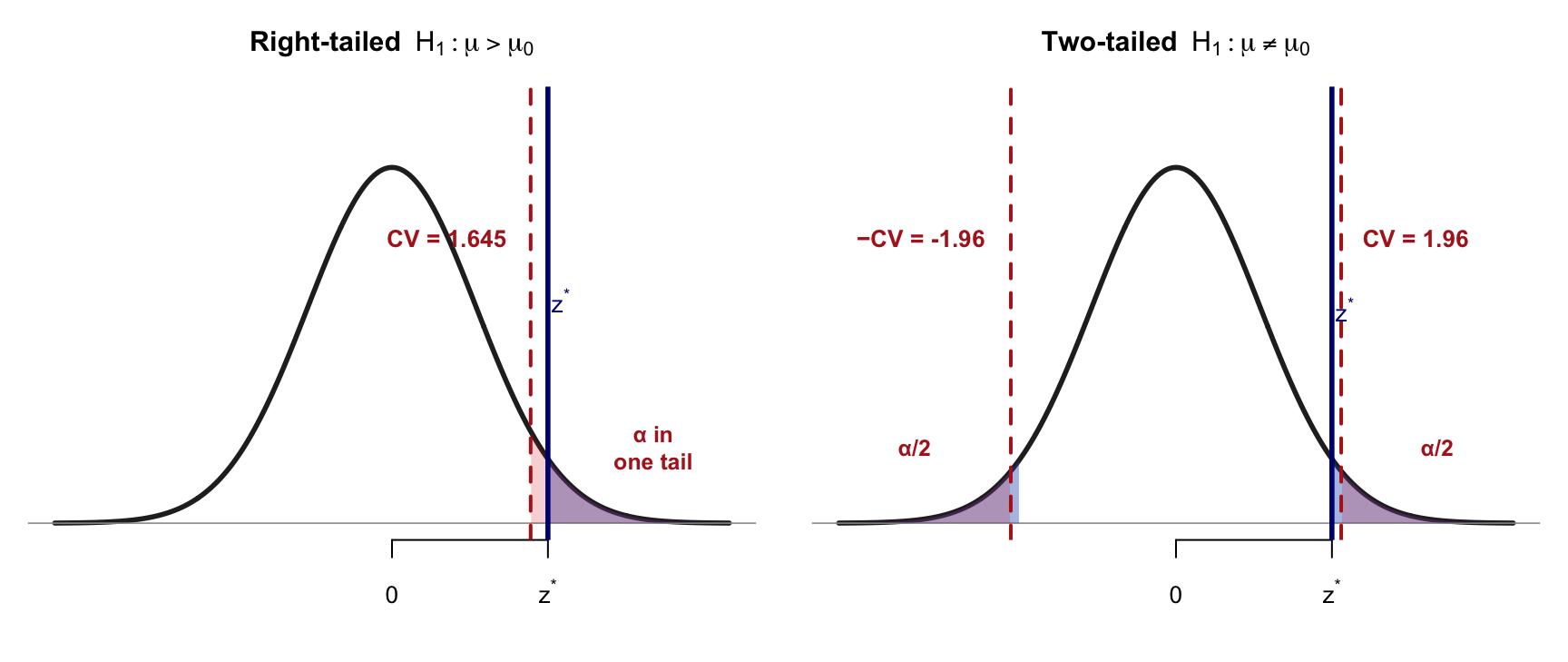
p-value area rejection region — test statistic (z*) – critical value (CV)
Standard Normal Z ~ N(0, 1)
Key features: Symmetric around 0 · Ranges (−∞, +∞) · Area under curve = 1 · No parameters needed
T-Student Distribution
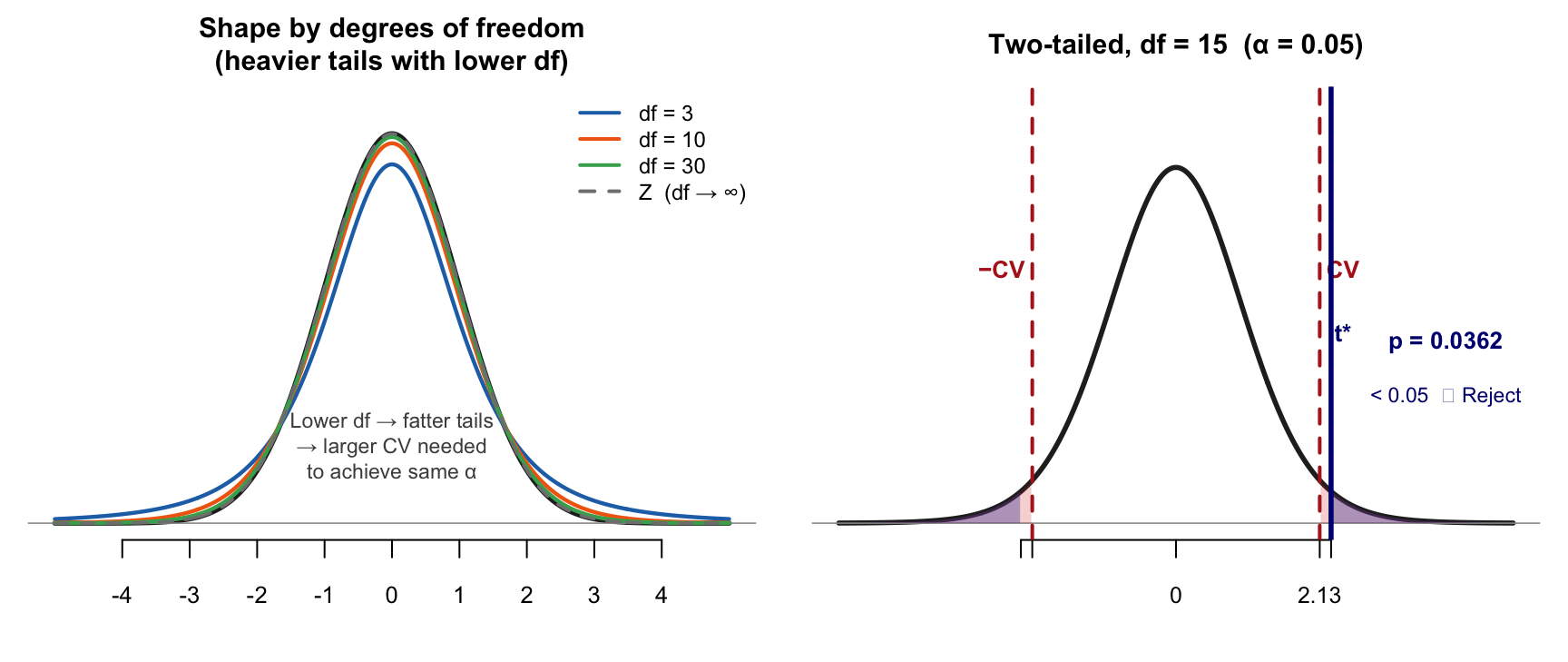
Key features: Symmetric around 0 · df controls tail weight · As df → ∞, t → Z · Always check df first — it changes the CV
Chi-Square Distribution (χ²)
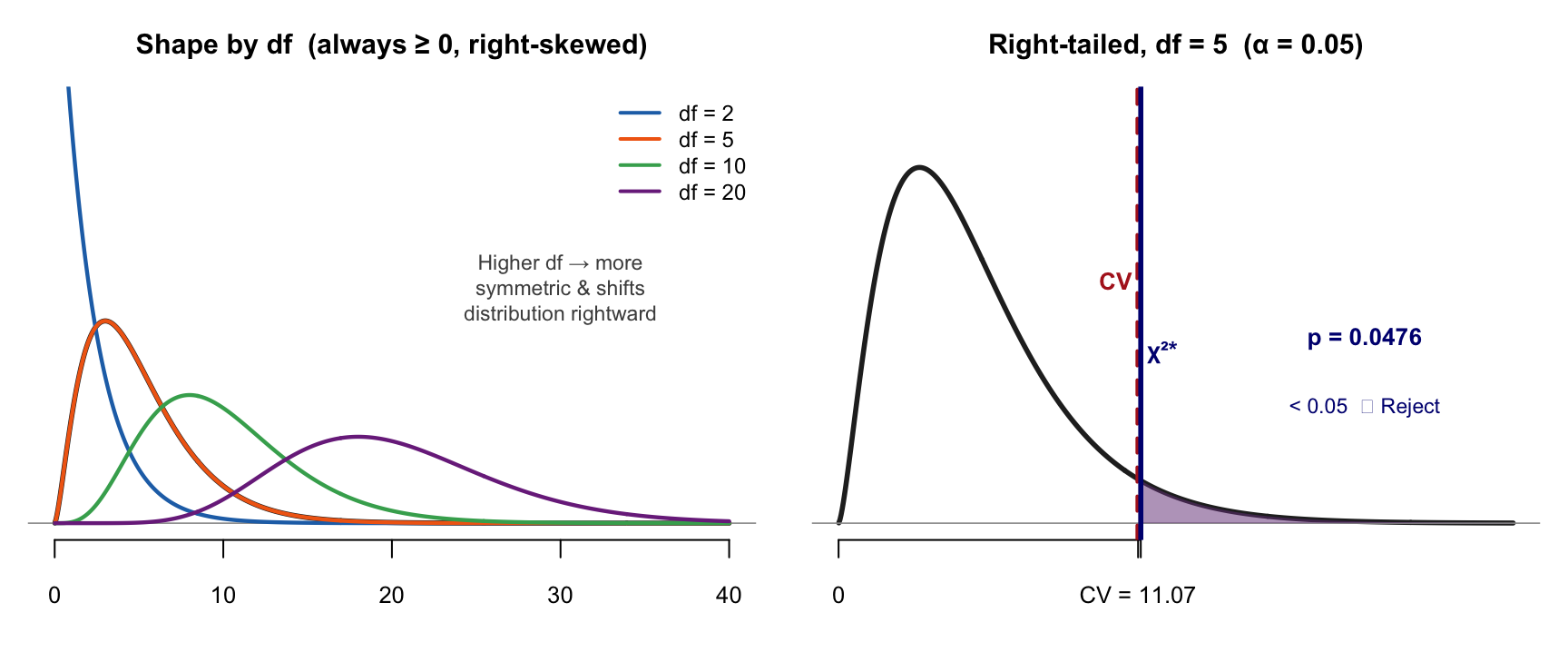
Key features: Values always ≥ 0 · Right-skewed · Only right-tail matters · Uses: goodness-of-fit, independence tests, variance tests
F Distribution
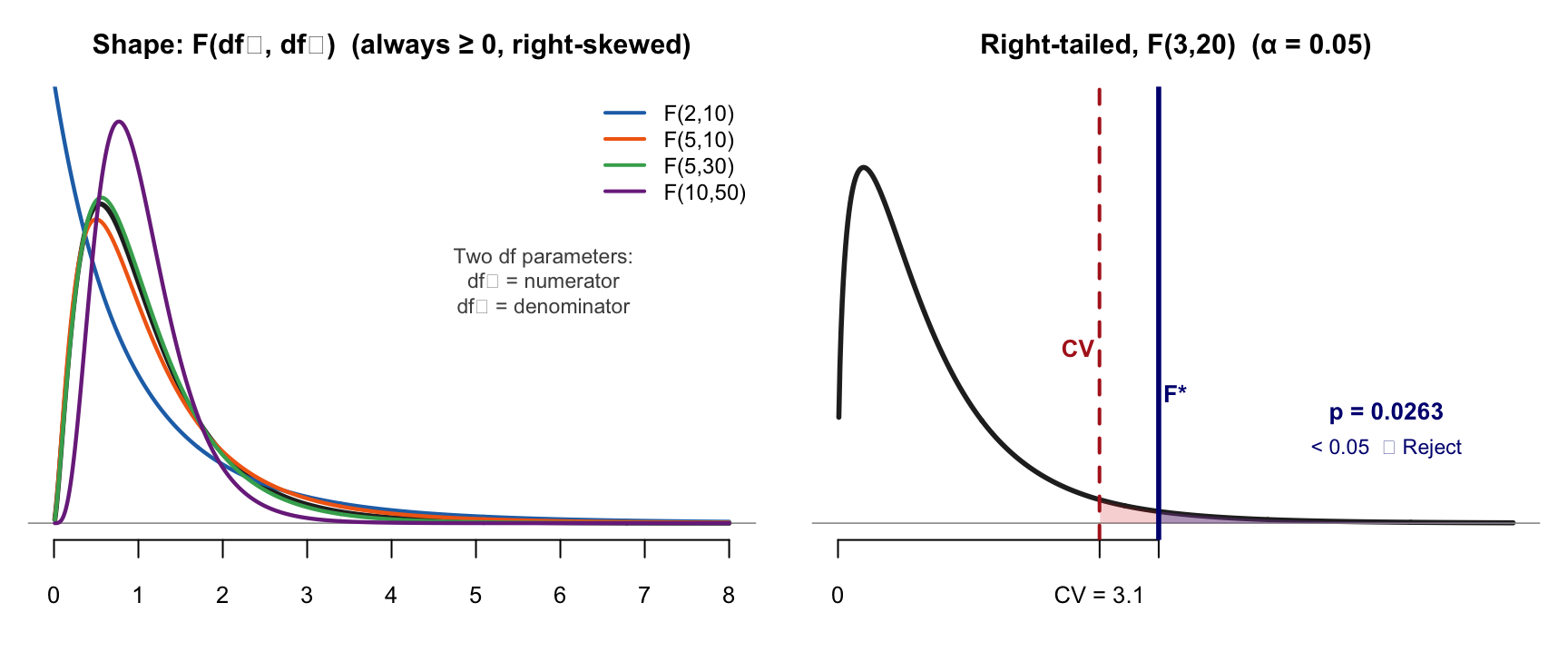
Key features: Values always ≥ 0 · Right-skewed · Two df parameters · Uses: ANOVA, overall regression F-test · F* = ratio of two variance estimates
Summary: All Four Distributions
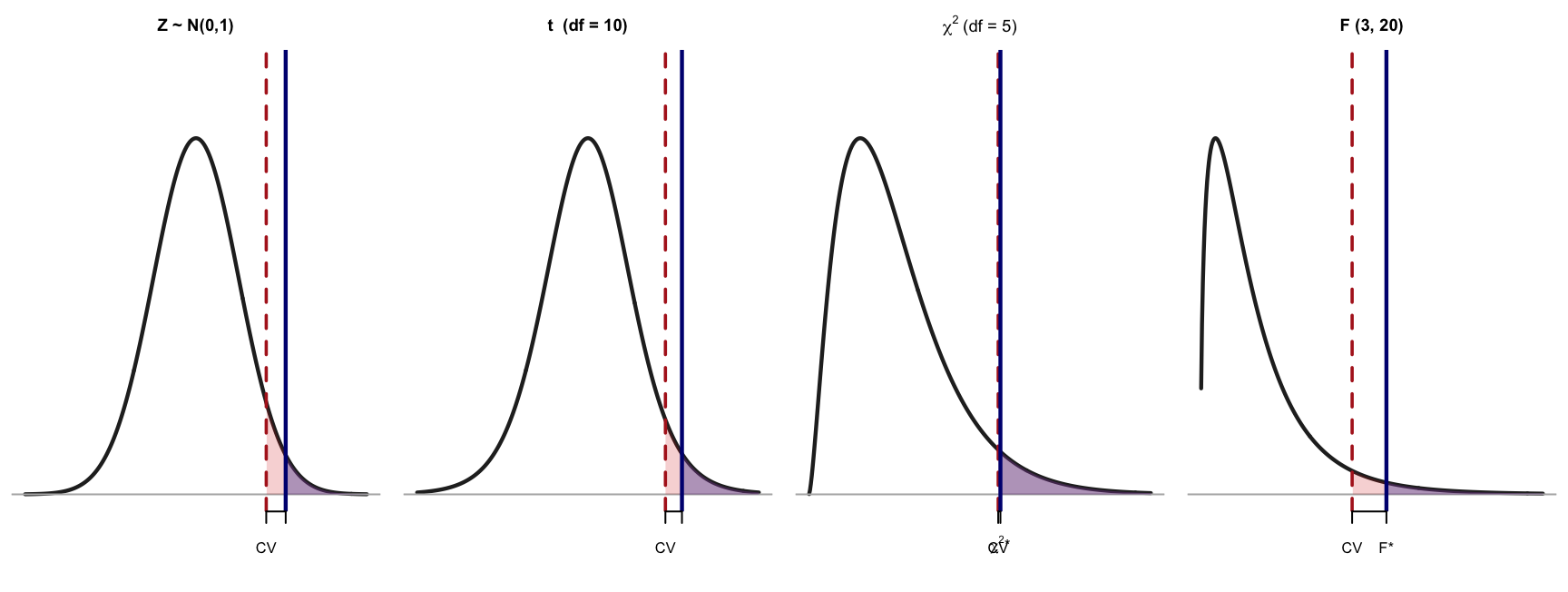
| Distribution | Symmetric? | Range | Typical test direction | # of df |
|---|---|---|---|---|
| Z | ✓ | (−∞, +∞) | one or two-tailed | — |
| t | ✓ | (−∞, +∞) | one or two-tailed | 1 |
| χ² | ✗ | [0, +∞) | right-tailed | 1 |
| F | ✗ | [0, +∞) | right-tailed | 2 (df₁, df₂) |